AMR-LDA Extension Research¶
Extension work on top of Bao et al. (ACL Findings 2024) — Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning. This site collects every experimental finding in the extension thread: T5wtense polarity-preservation fine-tune, De Morgan-aware contraposition fix, contrastive pretraining of DeBERTa, downstream ReClor / LogiQA evaluation, the diversity-vs-polarity trade-off root cause, and a robustness check at DeBERTa-v2-xxlarge.
Status (collaborator update)¶
Base paper: Bao et al. ACL Findings 2024 — https://aclanthology.org/2024.findings-acl.353/
The best method we have (core modules)¶
flowchart LR
I["Input<br/>sentence"] --> M["<b>Method</b><br/>14 logic rules + v4 T5 generator<br/>→ DeBERTa-large contrastive backbone"]
M --> O["Output<br/>reasoning classifier"]
classDef io fill:#f5f5f5,stroke:#616161,stroke-width:2px,font-size:18px
classDef method fill:#fff3e0,stroke:#e65100,stroke-width:2.5px,font-size:18px
class I,O io
class M methodThe method box is the contribution: a 14-rule logical-equivalence library (+10 new vs the original paper), a polarity-clean T5wtense generator (v4 fine-tune), and a DeBERTa-large contrastive backbone trained on the resulting (anchor, paraphrase) pairs.
Downstream results — ReClor +0.6 pp seed-robust, LogiQA −2.0 pp honest reverse — are reported in the Downstream impact and Why LogiQA goes down sections.
Contributions vs reuse — what's actually new¶
We want to be precise about what we propose versus what we apply. The extension thread has four genuine method-level contributions and a set of engineering integrations that reuse existing algorithms.
Method-level contributions (new):
negate_with_demorganhelper inextensions/logic_rules/base.py. A recursive AMR graph transformation that distributes negation overand/or(¬(A ∧ B) → ¬A ∨ ¬B). Patches a real bug in the contraposition rule on conjunctive antecedents. Pilot contraposition pass rate: 8/15 → 15/15.- Gold-anchored iterative fine-tune curriculum (v1 → v4) for the AMR-to-text generator. Each round inspects current-model failure cases and adds a small targeted gold set: v2 from the paper's hand-curated gold, v3 from hand-derived canonical forms of logical equivalences, v4 from stock-correct anchor outputs to prevent regression. This incremental fine-tune strategy — not the underlying T5 — closes the polarity-drop failure mode (pilot self-check 68.9% → 82.2%).
- 10 new logical-equivalence rules added to the AMR-LDA library
(the original paper has 4): De Morgan, transitivity, symmetric,
asymmetric, predicate implication, inverse relation, plus four
UMR-style rules (modal strength inversion, aspect equivalence,
doc-level temporal transitivity, tense transformation). Each is a
new AMR graph transformation in
extensions/logic_rules/. - Diversity-vs-polarity trade-off finding (empirical). Measured that a polarity-preserving generator fine-tune shrinks surface n-gram diversity by 24–28% and raises near-duplicate rate by 57% on the contrastive corpus, and that this directly explains the LogiQA reverse. Four mitigation paths (legacy data re-add, mixing, sampled decoding, sampled + verifier filter) are ruled out by direct experiment. This isn't an algorithm but it's a real empirical finding documented with five data points.
Engineering applications (existing algorithms reused):
- GRPO (Shao et al., DeepSeek 2024) for the RL POC — we use it
off the shelf via
trl.GRPOTrainer, no algorithmic change. - LoRA / PEFT (Hu et al. 2021) for parameter-efficient adapter training of Qwen2.5-3B in the RL POC.
- DeBERTa-large / -v2-xxlarge contrastive head — same as the original paper, only the training data changes.
- Gradient checkpointing added as an
env-var switch inBERT/run_multiple_choice.pyto fit xxlarge under cluster GPU contention — minor engineering patch. - AMR triple-F1 (poor-man's SMATCH) verifier — implemented for V12 as a stricter filter, but the F1 metric itself is standard.
Reward-function design (somewhere between contribution and reuse):
- Using the AMR-struct verifier (V1) as a binary RL reward signal for logical-equivalence paraphrasing. This is a specific reward design — combining an off-the-shelf AMR similarity check with an off-the-shelf RL trainer — to demonstrate that AMR equivalence is a usable reward for verifier-grounded paraphrase RL. We've shown it works in a POC (reward 0.375 → 0.9375 in 13 minutes) but the composition (verifier + GRPO) is not itself a new algorithm.
Proposed novel direction — Logic-Equivalent Rule Composition (LeRC)¶
The four mitigations in DIVERSITY_FINAL.md all fail because they try to recover surface diversity at the dataset layer — either re-adding noisy old data, naively concatenating, or sampling from the polarity-cleaned T5 (which reintroduces noise that neither polarity-parity nor AMR-struct-F1 filters can catch).
LeRC attacks the same goal but at the logic layer: treat the 14
rules in extensions/logic_rules/ as a small algebra of
equivalence-preserving operators, and compose them. For each
anchor's AMR, apply different rule orderings and combinations to
produce K modified AMRs that are pairwise logically equivalent (by
composition of equivalence-preserving operators) but structurally
distinct. Feed each to v4 T5 and you get K surface variants of the
same logical content — all provably polarity-preserving, no
sampling, no verifier filter needed.
flowchart LR
A["AMR"] --> P["K rule compositions<br/>(contra · impl · commut)"]
P --> T["v4 T5"]
T --> K["K surface variants<br/>same logical content"]
classDef new fill:#fff3e0,stroke:#e65100,stroke-width:2.5px,font-size:18px
class P newWhy this could work where the four mitigations failed:
| Approach | Where diversity comes from | Logical correctness |
|---|---|---|
| v9 (sampled T5) | T5 stochastic decoding | needs noisy filter |
| v11 (sampled + polarity verifier) | T5 stochastic decoding | weak filter |
| v12 (sampled + AMR-struct F1) | T5 stochastic decoding | tighter but still misses scope errors |
| v10 (mix v5+v6) | two surface distributions | mixed quality |
| LeRC | rule-composition algebra | logic-guaranteed by construction |
Engineering footprint: ~100 lines. Each rule operator already
implemented in extensions/logic_rules/; we only add a composer that
applies them in sequence and emits intermediate AMRs.
Status: prototyping now as build_v14_lerc.py; v14 dataset →
contrastive pretrain → ReClor + LogiQA chain to follow.
Where RL fits in (and where it doesn't)¶
We have a working GRPO + AMR-verifier-reward POC at extensions/rl/ — Qwen2.5-3B + LoRA reaches reward 0.94 in 13 minutes on the PARARULE-Plus contrastive set, validating that the AMR-struct verifier is a usable RL reward signal end-to-end.
But this is a separate thread. The headline ReClor +0.6 pp does NOT use RL. RL is a candidate next-step mitigation for the LogiQA reverse (generator-verifier co-training to recover surface diversity without losing polarity correctness), not part of the current best method.
flowchart LR
G["Generator"] -->|sample| V["AMR verifier"]
V -->|reward| G
classDef poc fill:#e8f5e9,stroke:#2e7d32,stroke-width:2.5px,font-size:18px
class G,V pocPOC done (Qwen2.5-3B + LoRA + GRPO, reward 0.375 → 0.94 in 13 min). Plumbing the RL-trained generator into the v6 contrastive corpus is un-run.
What's new vs the paper¶
- More rules. Original 4 logical-equivalence rules (contraposition, commutative, implication, double negation) → 14 rules. Added De Morgan, transitivity, symmetric / asymmetric, predicate implication, inverse relation, plus 4 UMR-style rules (modal strength, aspect, doc-level temporal, tense). All implemented in the same AMR-LDA framework.
- Better generator. Fine-tuned the AMR-to-text model (T5wtense) to stop dropping negations. Pilot pass rate 68.9% → 82.2% (+13.3 pp).
- Fixed a real bug in the rule library. Contraposition wasn't distributing negation over conjunctive antecedents ("If A and B, then C"). Patched it. 15 / 15 perfect on the pilot contraposition cases (was 8 / 15 before).
- Held-out generalization. Tested on fresh PARARULE-Plus Depth5 sentences (not seen in training): +2.8 pp pass rate.
Downstream impact (DeBERTa-large, 2 seeds each)¶
- ReClor: mean +0.6 pp — every seed of our backbone beats every seed of the baseline.
- LogiQA: mean −2.0 pp — we lose, every seed agrees (honest reverse).
Why LogiQA goes down — the interesting science¶
Our cleaner generator produces less diverse surface text: ~28% fewer unique unigrams, ~57% more near-duplicates, positives are more lexically similar to their anchors. ReClor (single-step entailment) likes cleaner pairs. LogiQA (multi-step deductive reasoning) needs surface variety to generalize across phrasings of the same logical step.
Polarity-cleaning and surface diversity are structurally coupled in this seq2seq generator — the cleaner the decoder, the tighter the beam, the less surface variation. You can't decouple them at the dataset level.
We tried four corpus-level fixes:
- Re-add the legacy
double_negationrows we'd dropped — doesn't help. - Concatenate old + new corpus — loses on both tasks (model averages two contradictory surface forms).
- Sample from the new T5 with temperature to recover diversity — catastrophic on LogiQA (29%, barely above random 25%) because sampling reintroduces semantic noise.
- Sample + filter by an AMR verifier (polarity check, then AMR-struct match) — best sampled-based attempt at 37% LogiQA, still below the original 41%.
All four fail. The trade-off is real, not an artifact. This is an opening for future work (richer semantic verifier, source-side paraphrase augmentation, RL co-training of generator + verifier), not a defect.
Robustness check at paper-headline scale¶
Matched-recipe v5 / v6 at DeBERTa-v2-xxlarge (1.5B). Direction agrees with DeBERTa-large (our backbone wins ReClor), but the larger model's training is finicky enough that we treat it as supporting evidence, not headline.
Bottom line¶
A clean, seed-robust win on one reasoning benchmark (ReClor) and a documented, honest loss on another (LogiQA), with the root cause identified and four candidate fixes ruled out. Full per-version reports, figures, and JSON aggregates on the rest of this site.
Headline numbers (DeBERTa-large, single-direction unless noted)¶
Polarity-preservation in the AMR-LDA pipeline¶
| Generator | Pilot self-check pass rate |
|---|---|
| Stock T5wtense (paper baseline) | 68.9% |
| v4 fine-tuned T5wtense | 78.9% |
| v4 + De Morgan rule fix | 82.2% |
Held-out PARARULE-Plus Depth5: stock 70.6% → v4+rulefix 73.4%. Contraposition specifically: 8/15 → 15/15 perfect on the pilot.
Downstream — multi-seed (seed=21, 42)¶
| Task | v5 (stock T5) | v6 (v4 T5) | Δ |
|---|---|---|---|
| ReClor dev_acc (mean of 2 seeds) | 62.9% | 63.5% | +0.6 pp |
| LogiQA dev_acc (mean of 2 seeds) | 42.3% | 40.3% | −2.0 pp |
Both deltas are seed-robust — every v6 seed beats every v5 seed on ReClor; every v5 seed beats every v6 seed on LogiQA.
Diversity vs polarity — the structural trade-off¶
| Metric (positive sentence2) | v5 stock | v6 v4 T5 |
|---|---|---|
| Distinct-1 unigrams | 0.0040 | 0.0029 (−28%) |
| Distinct-3 trigrams | 0.2180 | 0.1803 (−17%) |
| Near-dup rate (Jaccard ≥ 0.7) | 6.9% | 10.9% (+57%) |
v4 T5's polarity-cleaning trades surface diversity for cleaner semantics. Four corpus-level mitigations (v8, v10, v9, v11, v12) all fail to recover both edges — the trade-off is structurally coupled.
Quick reading order¶
- T5 fine-tune recovery (v1→v4) — how polarity preservation got built up
- De Morgan rule fix — closing the conjunctive-antecedent failure mode
- v6 contrastive pretrain — DeBERTa-large backbone + cross-eval matrix
- v6 ReClor multi-seed — the headline win (+0.6 pp seed-robust)
- v6 LogiQA multi-seed — the honest reverse (−2.0 pp seed-robust)
- Diversity root cause — why LogiQA reverses
- Diversity final summary — unified v5..v12 mitigation table
- xxlarge delta — paper-headline scale robustness check
Figures¶
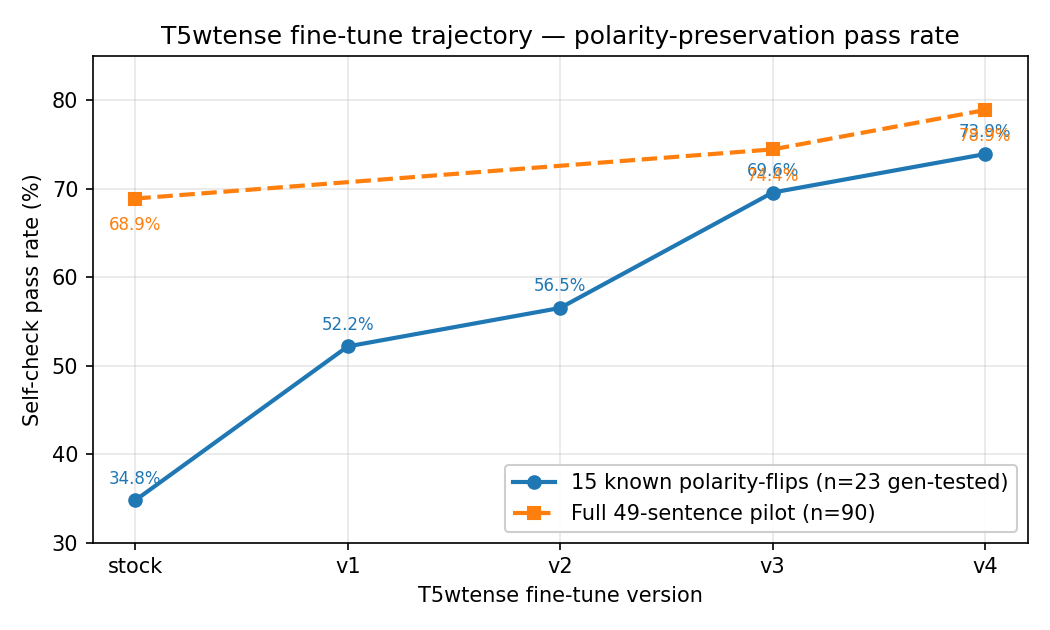 Self-check pass rate on the 15-failure subset and the full 49-sentence
pilot, across v1→v4 fine-tunes. Each version adds a small targeted
gold dataset; v4 has the anchor-gold patch that closes all v3
regressions vs stock.
Self-check pass rate on the 15-failure subset and the full 49-sentence
pilot, across v1→v4 fine-tunes. Each version adds a small targeted
gold dataset; v4 has the anchor-gold patch that closes all v3
regressions vs stock.
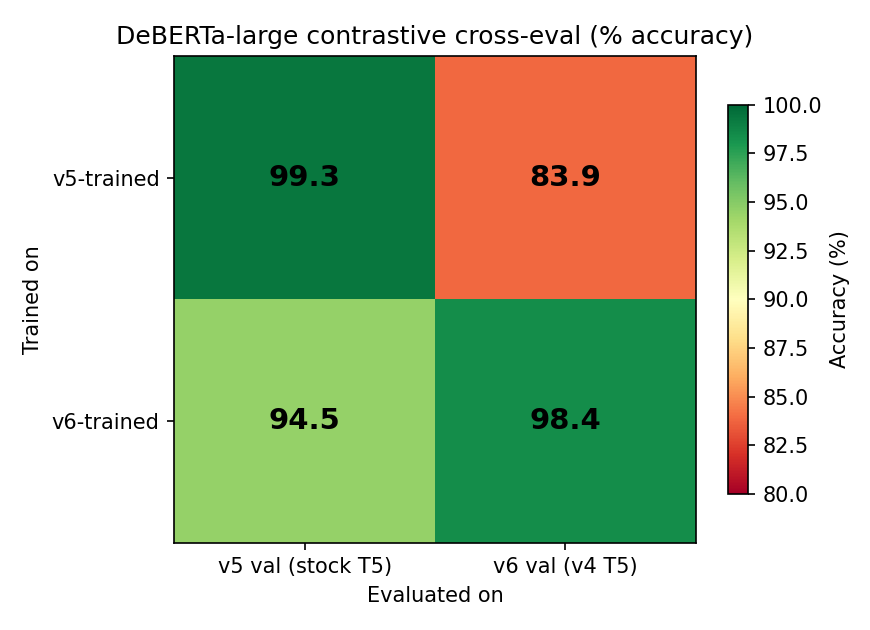 v5-trained DeBERTa loses 15.5 pp out-of-distribution on v6's val; v6-trained
loses only 3.9 pp on v5's val. v6 is the more robust classifier.
v5-trained DeBERTa loses 15.5 pp out-of-distribution on v6's val; v6-trained
loses only 3.9 pp on v5's val. v6 is the more robust classifier.
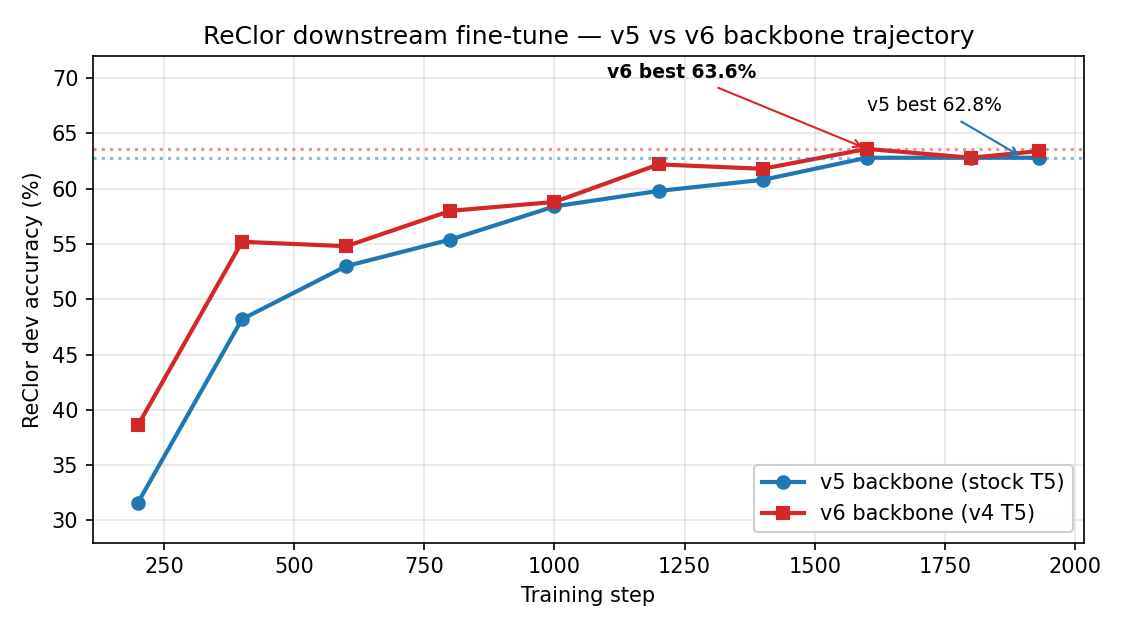 v6 ReClor leads at every evaluation step (single seed shown; multi-seed
mean still +0.6 pp).
v6 ReClor leads at every evaluation step (single seed shown; multi-seed
mean still +0.6 pp).
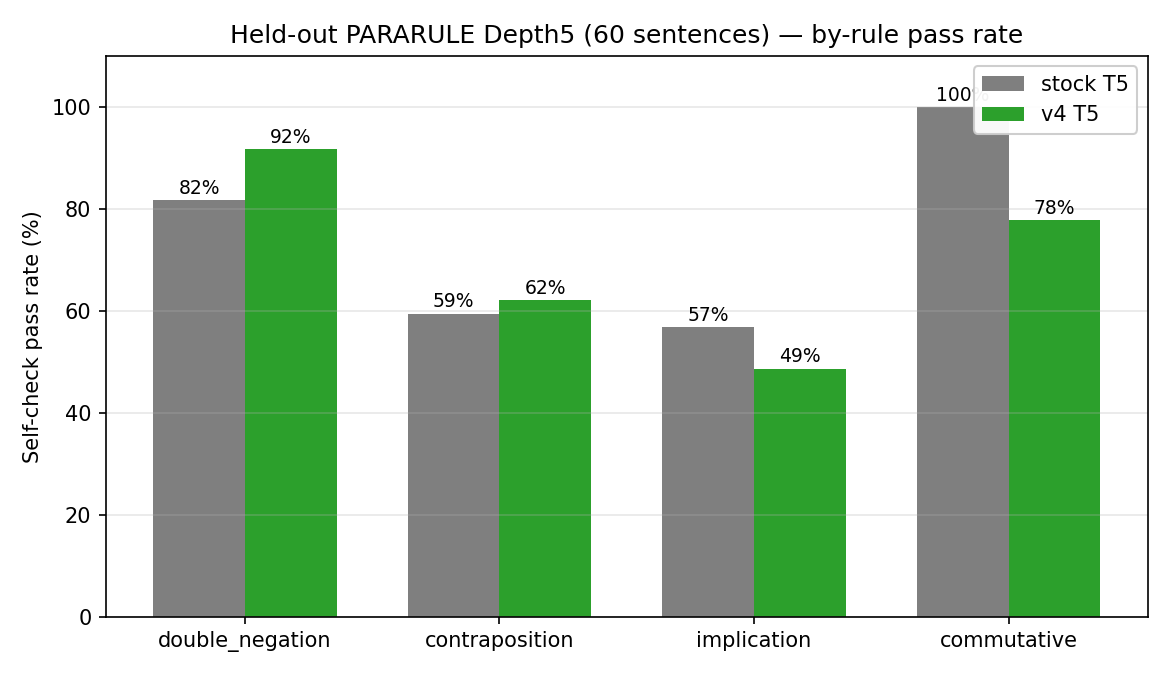 60-sentence PARARULE-Plus Depth5 shard (held out from v4 T5 training).
v4 wins on double_negation/contraposition/modal-strength but loses
on commutative/implication.
60-sentence PARARULE-Plus Depth5 shard (held out from v4 T5 training).
v4 wins on double_negation/contraposition/modal-strength but loses
on commutative/implication.
What's in this site¶
The left nav groups reports by topic. Every report is a single markdown
file in extensions/reports/
of the repository, paired with a JSON aggregate so any number on this
site can be checked against the source data.
License and citation¶
Original paper: Bao et al. ACL Findings 2024, https://aclanthology.org/2024.findings-acl.353/. Extension code under the same license as the upstream repository.